
Data / Metadata curation work in our seismic data archive
Welcome, haere mai to another GeoNet Data Blog. The topic of today’s blog is to discuss how we curate and maintain the data stored in our archive.
This blog is written with a focus on our seismic data, although we occasionally apply the principles discussed here to other data domains. Since these processes are for handling our MiniSEED data, the tools and methods used here can be applied to other domains stored in this format including Coastal Sea Level (for tsunami monitoring), Geomagnetic, and Acoustic/Infrasound data.
Our Waveform Data Archive
GeoNet’s seismic data catalogue consists of two related components. The first is the raw waveform data. For many of our continuous time series data domains such as seismic, coastal sea level gauges and geomagnetic data. We collect data in a MiniSEED format. This format contains time series data encoded in short binary records, with minimal metadata limited to the station/stream name code and a few state of health and data quality flags.
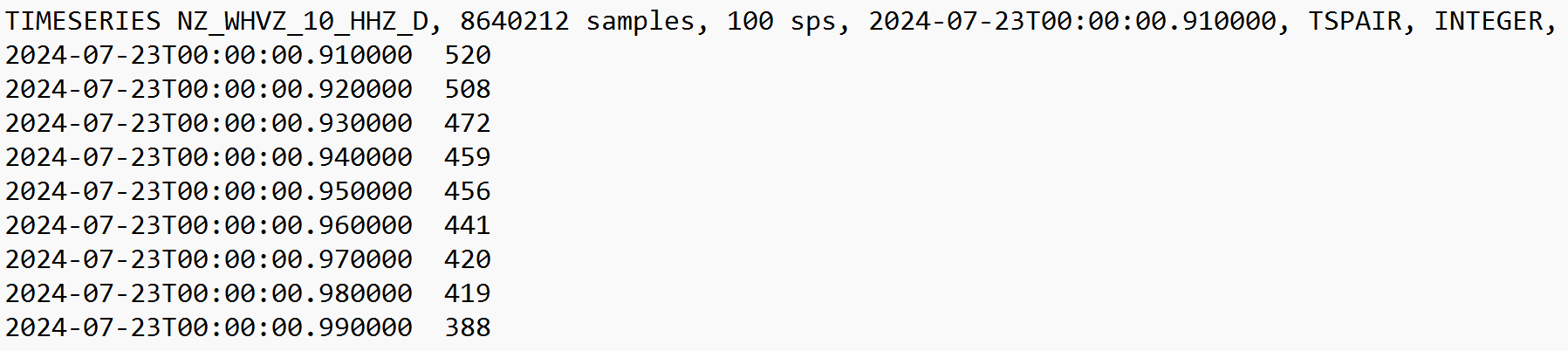
Ascii representation of a typical seismic MiniSEED file. The first line is the metadata header describing the contents of the file, followed by the time series data.
The second component of our seismic data catalogue is the metadata associated with each station and data stream. This metadata holds information such as what streams are available for each station, the elevation of each site, what instruments were used to collect the data, and the response of the instrument and datalogger.
All of the GeoNet sensor network metadata is stored in our publicly available Delta GitHub repository. From this repository, we build metadata and data availability information for several of our data access mechanisms. As we’ve noted before, Delta is our single source of metadata truth. If you use one of our data access mechanisms such as FSDN, you may be familiar with this metadata in the form of stationxml files or JSON responses.
One of the operational tasks we do at GeoNet is ensuring that the waveform data and metadata we provide are in agreement. We strive to ensure consistency across our datasets, but in the case of unexpected changes in field gear, errors in equipment configuration, or historical data with incomplete metadata, there can be inconsistencies. We try and identify and fix these wherever possible.
What is metadata?
Metadata put simply, is data about data, or data that describes data. You might find this term used in other fields such as photography, or telecommunications. In photography, metadata describes the shooting settings and conditions. This may include the time and date the photo was taken, the camera settings, and of course the type of camera and lens used to take the shot. In the Geonet context, metadata functions in much the same way. We keep records for each station and instrument saying when and where each piece of equipment was deployed. This is important to maintain the findability and accessibility of our data, important parts of the FAIR data principles.
What does archive curation involve?
Filename and Header corrections
The most common archive work we do is editing the metadata contained in the headers of the files in the archive. Remember we said earlier that this is restricted to the station/stream name code and a few state of health and data quality flags. This process does not alter the raw (ground shaking) time series data in any way. We focus on the most important metadata which is the channel identifier information, the Network, Station, location, and channel codes. We make sure this matches the metadata with the equipment we know was deployed in the field.
Most other changes to seismic metadata do not impact the data at a stream level in the archive since most of the other metadata we manage is not a part of the MiniSEED format. Since the rest of our metadata and metadata products are stored/built in our Delta GitHub repository, applying the appropriate changes to the metadata configuration files held there is usually sufficient to correct any errors in the metadata.
While we sometimes must make changes to the waveform data files in our archive, its relatively rare considering how many stations we have and how much MiniSEED format data we collect. An example might be if there was an error in a datalogger installed at a site and the waveform files arriving in our archive have a mistake in the header or the filename itself is not right. When we are deploying new equipment, to save time and difficulty in the field we often preconfigure the recording equipment with what stream names and metadata we expect to be recording. However, this can require making assumptions about the new installation. Last year we had to relocate one of our sites, HRRZ – Hathaway Farm, due to the planting and growth of a pine tree forest neighbouring the site that had begun limiting our access and interfering with radio comms. We installed the equipment alongside a nearby GNSS station, making a new seismic station HNCZ – Handcock Road. We expected the new sensor to be orientated to point north which is our ideal. Unfortunately, this was not achievable. We use different channel names to represent north aligned sensors, and sensors that are axial (not north aligned). Here the datalogger was configured to produce three streams with the names HHZ, HHN, and HHE (vertical, north, and east components), but with the unexpected orientation we had to correct these to the axial codes HHZ, HH1 and HH2. Fortunately for us we caught this issue quickly, so only a couple of days of data were saved with the wrong channel names before we could update the datalogger content.
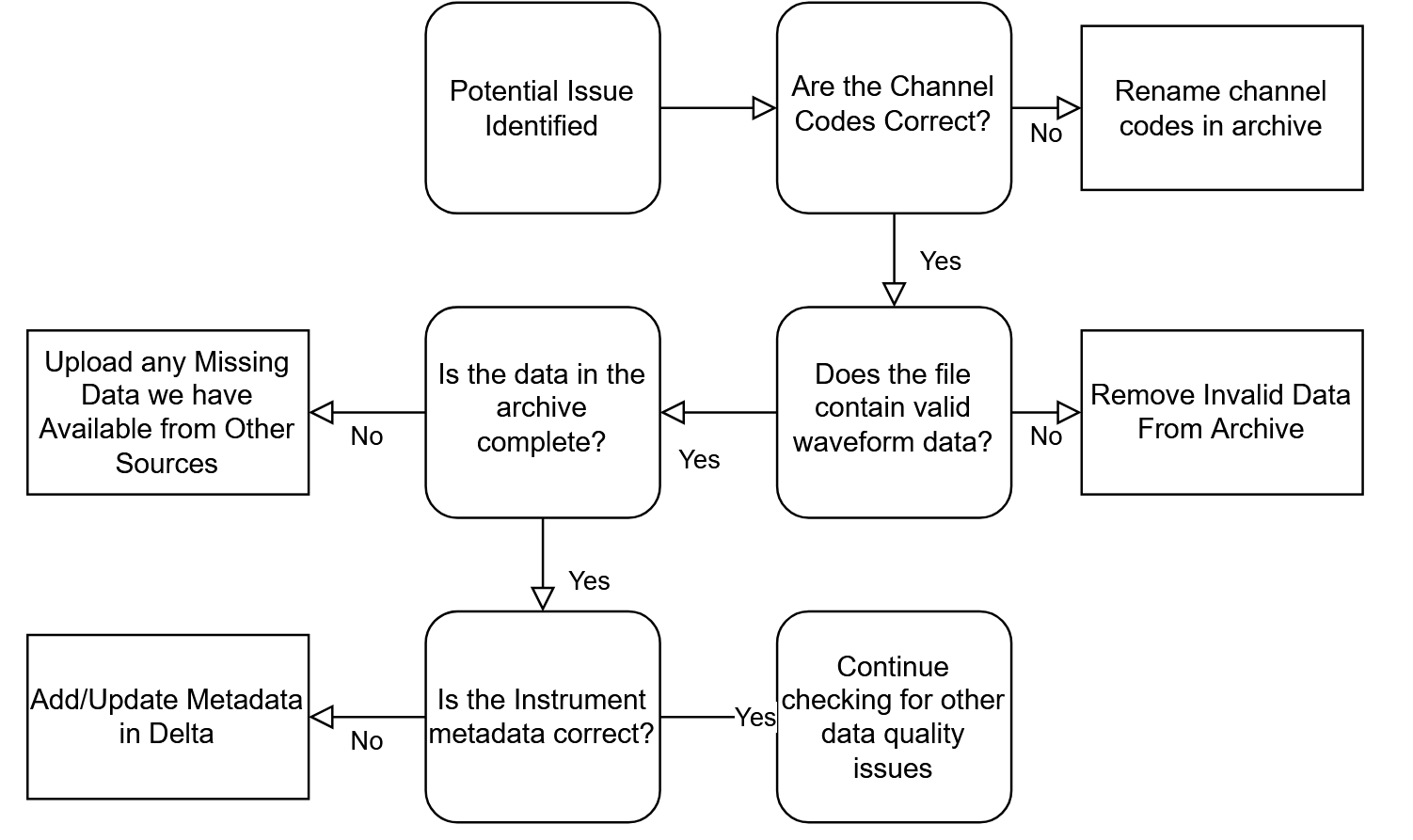
Flowchart of the main checks we make when looking at incomplete/incorrect data in our archive
Waveform Data Corrections
Up to now we have discussed work involving changes to the waveform filename and headers only. On occasion we will need to deal with the actual waveform data component of a file in our data archive. This is more complicated.
Sometimes we remove data files that contain no usable data, but only when we are extremely confident that this is the case. The most common source of these files is data recorded and ingested into our system that do not contain any signal originating from a sensor. In most cases, our sensor and datalogger are separate. If there is no connection between the sensor and the datalogger, either due to physical faults or software configuration issues, the datalogger will continue recording and sending “data” to our datacentres. However, this data will only contain very minor values caused by things like thermal fluctuations and random electrical noise in the datalogger. The data values are essentially “zeros” and have no meaning for anyone trying to use the data. Whenever we identify streams like this, we aim to remove them from our data access mechanisms to minimize confusion to data-users attempting to use that data stream, and to keep our dataset nice and tidy.

A broken cable at our tsunami monitoring gauge in Lake Taupo. When a cable snaps like this between the sensor and the datalogger, the datalogger will continue streaming junk noise, which we typically try to remove from the archive when we find it

Sometimes a hungry rodent chooses to disconnect our sensors for us. The data collection equipment continues running, but without a sensor properly connected this data is useless
Not everything we do is relabelling or removing data (as shown in the figure below, which is overview of archive corrections made to seismic data last year), we also we use similar processes to upload data recovered from sensors where real time streaming of data failed or was not available. Although we try to ensure our remote infrastructure equipment is sturdy, sometimes extreme weather like Cyclone Gabriel in 2023 damages the communication equipment at a site. This happened to one of our Gisborne stations, GRAS – Gisborne Response Grey Street. Fortunately for us the three strong motion recorders there were able to continue collecting data during much of this time. When we returned to repair the site, we were able to collect this data out of the recorders internal storage and manually upload it into our archive to fill in some of the gaps caused by the cyclone.
The Importance of Version Control
Version controlling data is a method of ensuring that data is never lost no matter what changes we make. This works by recording the original state of the data, either by preserving a hidden copy, or taking a snapshot of the changes made. Using version controls allows us to see the history of changes made to a dataset, and to recover its previous state if necessary; “unchanging a change”, so to speak. We use several version-controlled systems to store all the data in our archive, as well as our metadata databases. In the case of our waveform data, it is stored in Amazon AWS S3 buckets, while our metadata is stored in our Delta GitHub Repository.
Giving the data a bit of love
This work has historically been a relatively low priority, especially for older and less used data. As much as we love working on the newest and most exciting things and keeping up with all the needs of supplying accurate real-time data to our end-users, sometimes we need to go back and give some of our older data a bit of love. And there is a lot of it too! We currently have over 135TB of data in our cloud-based archives, and much of this data we make available freely through the AWS open data program. Click here to access any of our waveform or Delta metadata. And don’t forget to cite any GeoNet datasets that you use.
That’s it for now. If any of our data users reading this post find or know of any parts of our seismic data catalogue that are not perfect or you would like us to work on, please get in touch either via our Github based Help repo or email us at info@geonet.org.nz, we would love to help!
Ngā mihi nui.