
FAIR Data
Welcome, haere mai to another GeoNet Data Blog. Today’s blog is about FAIR data, what it is, why it’s important, especially to GeoNet, and what we are doing to try to make it more FAIR.
Most of you might not have heard of FAIR and might have no idea of it’s relevance to data. Let’s start by fixing that.
When we collect data, and GeoNet does a lot of that, we want people to be able to easily find and use those data. Imagine you’ve heard GeoNet has some data that might be useful to help you solve a problem or find out something you need to know. You first need to confirm there are data that might be useful, and based on what information is available, that that they will help solve your problem. Once you know the data exist, the next step is where, and how do you get hold of them. Are the data in a format you can easily use, either on their own or with other data you already have? Is the format something usually used for data of that type, or are they in a format you’ve never heard of before, and no one in your community is familiar with? Finally, assuming all those boxes are ticked, do the data have a licence that makes it clear what you can or cannot do with the data? We can condense all this into Findable, Accessible, Interoperable, and Reusable, which we refer to as FAIR Data Principles (FAIR for short).
FAIR data is a relatively new thing in data management and stewardship. As this is a blog we aren’t in the habit of referring to academic publications, but we’ll make an exception for this. In 2016, Mark Wilkinson and others published “The FAIR Guiding Principles for scientific data management and stewardship”, in the journal Scientific Data. Less than 10 years later, FAIR data is “all the rage”, and agencies like GeoNet are using those principles to make it easier for people like you to work with our data.
Why is FAIR important to GeoNet?
If you have ever looked at the Data Policy page of our website or read any of our data blogs, you’d realise that one of GeoNet’s core data principles is “open data”. To quote our website “All data and images are made available free of charge through the GeoNet programme to facilitate research into hazards and assessment of risk”. In other words, you can freely use all the data we collect. If you have any questions about what you are allowed to do with the data, the license is available via the Data Policy page of the website. While open data and FAIR data are not the same thing, if GeoNet data are FAIR, we are going a long way towards making practical use of our open data actually possible by everyone.
The first steps towards FAIR at GeoNet
GeoNet first started thinking about using FAIR data principles as guidelines around 2020, and first actively evaluated how well we were doing in 2021. We didn’t do it all ourselves as we used a FAIR Data Self-Assessment Tool from the Australian Research Data Commons (ARDC, a research data infrastructure facility), that was adapted to our needs by GNS Science colleagues. Our adaptation of ARDC’s FAIR Data Self-Assessment Tool is itself freely available.
How FAIR is FAIR?
Our scoring or evaluation process (we tend to use those words interchangeably) involves assessing datasets against certain criteria. In the ARDC assessment tool, each of F, A, I, and R have between two and five questions that represent those criteria, and for each question we chose the best answer as it applies to our datasets. Each possible answer has a score associated with it and by adding up the scores we are able to get a percentage value that represent how compliant the dataset is against each of F, A, I, and R. Those individual values can then be added up to get a total FAIR score, which is also a percentage. A FAIR score of 100% means a dataset is fully compliant with FAIR principles.
Some of the questions require some careful thought and some degree of interpretation, but to make the process more robust we typically do it in pairs, one person who knows a dataset well, and one who is less familiar. And we then get together as a group to cross check and make sure we are consistent across all datasets.
Datasets we evaluate fall into two categories, GeoNet datasets, and GeoNet datasets that are also part of the National Earthquake Information Database (EID), one of the Aotearoa New Zealand’s Nationally Significant Collections and Databases that is managed by GNS Science. The distinction is somewhat arbitrary, but it's useful to keep it as we’ll refer to differences later.
Datasets, not tools or applications
FAIR principles and guidelines are mostly designed for evaluating datasets, not tools or applications used to deliver those datasets, but as access to datasets is important a dataset provider would benefit from considering FAIR when building tools and applications. To give an example, we have a dataset of volcanic sulphur dioxide emission rates collected automatically using scanDOAS instruments. Those data are made available using our Tilde low-rate data delivery application. We evaluate the scanDOAS data, not Tilde that provides scanDOAS data. That scanDOAS data are available through an application that has published standards and protocols improves the “A” score in FAIR, and that the data are available in recognised CSV and JSON formats, improves the “I” score in FAIR.
FAIR scoring in 2021 and 2024
In 2021, we scored 10 GeoNet datasets and 9 EID datasets. In 2024, we scored 20 GeoNet datasets and 10 EID datasets. The difference in the intervening three years is that we started collecting some new datasets and developed some new dataset “products”.
For datasets we scored in both 2021 and 2024, we are able to see any changes in FAIR scores. For datasets newly scored in 2024, we have a benchmark for future comparison.
Comparing 2024 against 2021
Overall, we saw a mean improvement in FAIR score of 14% between 2021 and 2024. One score went down (more on that later), the biggest increase was 39%, and the spread (standard deviation) was 11%, including a couple of scores didn’t change.
The biggest improvement (39%) was for the historic volcanic activity dataset, then 32% for the acoustic waveform archive, and 26% for DART tsunami gauge data.
In 2021, we had three datasets with scores above 90% and two more above 80%. By 2024, we had 12 with a score of 90% or above, and a further 8 above 80%.
The one dataset whose score declined between 2021 and 2024 was the EID fault rupture models dataset. This dataset hadn’t changed between 2021 and 2024, and the difference was probably due to variation caused by having different people evaluate the dataset three years apart.
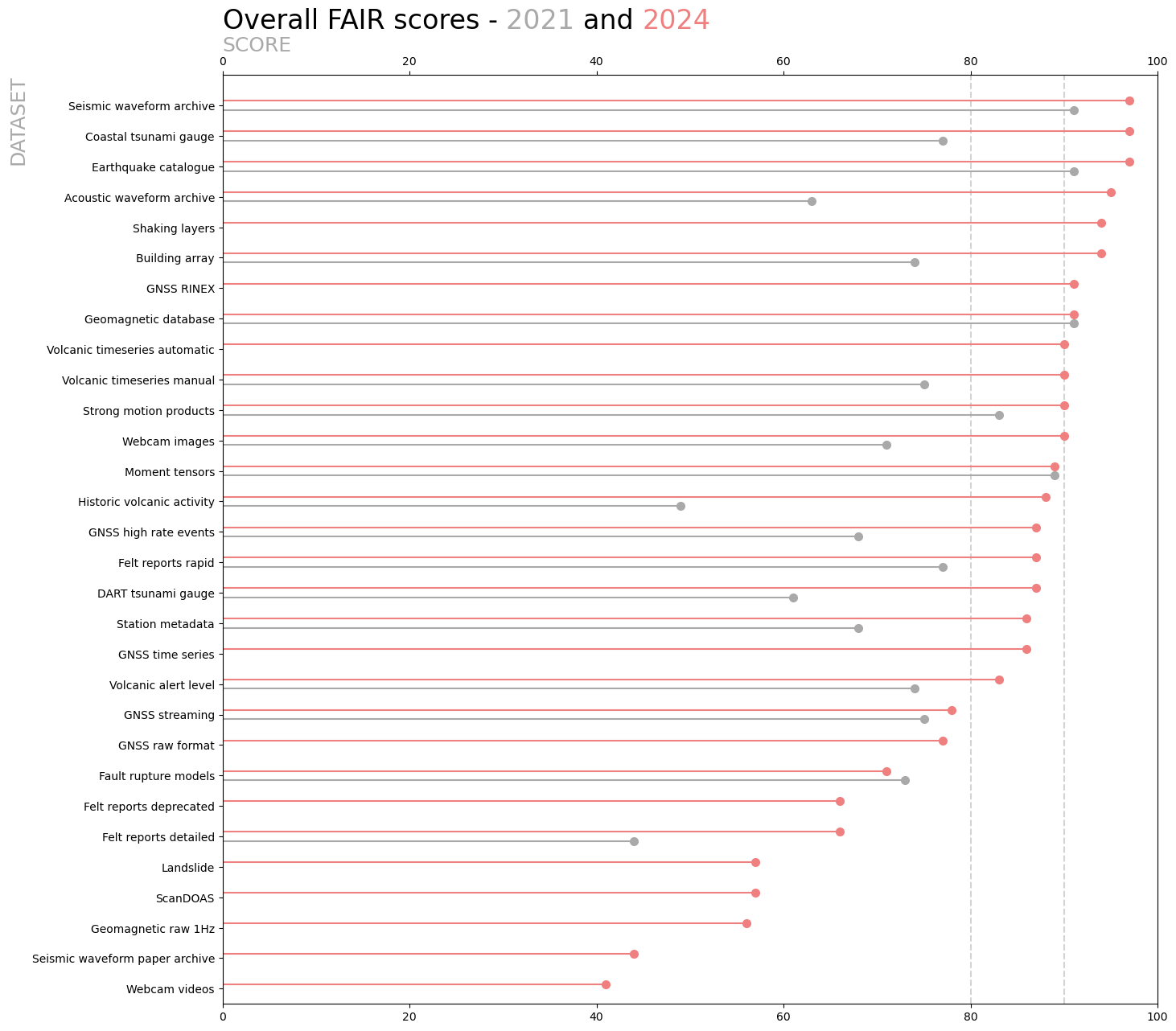
A summary of changes in FAIR scores between 2021 and 2024. If a score is shown only for 2024, then the dataset wasn’t evaluated in 2021. Datasets are ordered top to bottom by their 2024 score.
How we improved FAIR between 2021 and 2024
The improvement in FAIR scores between 2021 and 2024 didn’t happen by magic. For most datasets, prior to 2021 we had made little focused effort to improve FAIR (though we’ve always worked to make our data generally available and usable), largely as we didn’t know how well, or poorly, we were doing.
The 2021 results prompted some serious action by our Science Operations and Data team, and EID dataset managers. Our biggest and best initiative was ensuring every dataset was in GNS Science’s Dataset Catalogue. The Dataset Catalogue is a human and machine readable (i.e. automatically by computer) catalogue that contains information about a dataset, citation guidelines, the format the data are available in, and perhaps most importantly (at least for FAIR), a Digital Object Identifier (DOI). A DOI is unique to a dataset, and can be used as a reference to permanently identify the dataset. A DOI looks like https://doi.org/10.21420/0S8P-TZ38, this one is for the GeoNet Aotearoa New Zealand Earthquake Catalogue. In our case, DOIs points back to their GNS Science Data Catalogue entry.
In ARDC’s FAIR scoring scheme, a complete GNS Science Dataset Catalogue entry, including a DOI, gives 100% for “F”. This is because the GNS Dataset Catalogue uses a recognized standard for dataset descriptions, so by using and describing our datasets there, we are sure that both humans and machines are able to find the dataset and access its general information.

The GNS Science Dataset Catalogue entry for the Aotearoa New Zealand Earthquake Catalogue includes the time, location and magnitude of all earthquakes we have a record of in NZ. The first earthquake listed in the catalogue occurred in 1460,.
Other initiatives were more targeted to individual datasets. The biggest 2021-24 improver, the historic volcanic activity dataset, was in pretty poor shape in 2021, with a FAIR score of 49%. The data were in two reports, and in spreadsheets available only within GNS Science. We tidied the two spreadsheets containing the data, ensuring all rows were formatted consistently, documented all the data fields, and described decisions we’d made in formatting and preparing the data files. We then converted both spreadsheets to CSV format, as that is easier to work with than a proprietary spreadsheet format, and published the dataset and documentation in GeoNet’s data GitHub repository. These changes boosted FAIR from 49% to 72%, and we gained a further 16% by creating the GNS Science Dataset Catalogue entry and assigning a DOI, getting to a final score of 88%.
The beauty of having and using a FAIR scoring assessment tool is that it can help data providers such as GeoNet identify what actions could be taken to make the data more accessible and usable.
The sky is not the limit
While there are always actions we can take to improve FAIR, there are limits, and not just because you can’t score more than 100%!
The nature of the web service (computer interface) that is used affects the “A” (accessible) in FAIR. If there is a standard web service interface (API) and protocol you can use, you score full marks for one of the “A” questions. But if that doesn’t exist, or you have decided not to use it for some reason, you can never get a perfect 100% for “A”. This applies to all the datasets we provide through Tilde. Tilde provides data from several very different data domains, so there is no single existing API we can use, so we defined and use our own.
Another place where we often can’t score full marks is when a dataset doesn’t have an agreed set on concepts, categories, and properties (an ontology to experts in that field). If we have to write our own, we can never get 100% for “I” in FAIR as there isn’t a “community standard”. We always strive to use accepted standards where we can, for example our raw seismic waveform data, and by extension acoustic/infrasound and geomagnetic, use the miniSEED format which is appropriately recognized. Likewise, the RINEX format we use for raw GNSS data is internationally recognized, with a published ontology.
What work doesn’t really improve FAIR
While a lot of the work we do to improve the management and stewardship of our datasets will contribute to an improved FAIR score, there are substantial pieces of work that don’t change FAIR at all.
We’ve already mentioned that FAIR evaluates datasets not applications, so it won’t come as a big surprise that a major project to replace our old low rate delivery application FITS with a more modern Tilde had no effect on FAIR scores. This is because both FITS and Tilde use a vocabulary that was developed and used only by us, as there is no suitable commonly agreed standards. So, from a FAIR perspective, both in-house developed API services score the same. What does make a difference is that data are available through an application, rather than “phone a friend” or some other “backdoor” means. This means that some datasets that we’ve added to Tilde (that weren’t previously in FITS) stand out as big improvers.
What’s next?
The three years between our 2021 and 2024 FAIR evaluations is longer than we’d like. In future, we are thinking to do at least a quick review once a year.
While we’ve talked exclusively about the ARDC FAIR Data Self-assessment Tool, as that is what we’ve used, there are other tools available. We’ve done some very limited comparison with the F-UJI Automated FAIR Data Assessment Tool. We got quite different scores as F-UJI is only measuring the dataset description in the GNS Dataset Catalogue and is heavily focused on how that is formatted and what standard it is using. We plan to look at other FAIR evaluation options in the future.
That’s it for now
Whew! That is quite a lot of material. Thanks for making it to the end. FAIR is a really important concept in data management and stewardship, so we think it deserves its space, we hope you agree.
While we spent a lot of space talking about FAIR numbers, they reflect the usability of the data and that is the most important consideration. What the FAIR scores do is highlight areas we can improve, and indicate how much we have improved, and everyone likes seeing that. A DOI makes such a big difference to the “F” in FAIR, and is such a useful reference to a dataset, there is no reason not to have one. And finally, the “F” in FAIR is relatively easy because we have the GNS Dataset Catalogue so we can easily leverage community standards such as the DOI identifiers system. With “A” and “I” things are more difficult due to natural caps or ceilings, especially if your datasets are not part of a wider international system.
You can find our earlier blog posts through the News section on our web page just select the Data Blog filter before hitting the Search button. We welcome your feedback on our data blogs and if there are any GeoNet data topics you’d like us to talk about please let us know!
Ngā mihi nui.
Contact: info@geonet.org.nz